
티스토리 뷰
컴퓨터가 자연어를 이해하는 기술이 크게 발전한 이유중 하나
OoV 해결(완화)
OoV : Out of Vocabulary
단어 집합에 존재하지 않는 단어들이 생기는 상황 (TrainSet 당시 없던 단어가 TestSet에 있을 경우)
OoV(Out of Vocabulary)문제란 무엇인가?
- 위 내용을 더 간략하게 아래와 같이 이야기 할 수 있다.
- Train데이터로 만든 단어 사전에 없는 단어가 발생
"단어 사전에 없는 단어" 자세한 설명
- 학습(Train)데이터에 대해 모든 단어를 토큰화 하여 Vocabulary를 만들고,
그 Vocabulary를 기준으로 정수 인코딩(단어를 컴퓨터가 계산가능하도록 숫자로 표현)을 하게된다. - 이때, 실 예측(Test)데이터에 학습(Train)데이터에 없는 새로운 단어 토큰이 들어올 경우
- 이를 OoV(Out of Vocabulary)문제 라고 한다.
OoV - <UNK>
- <UNK>
: unknown token - 새로운 단어 토큰이 들어 왔을때 vocabulary에 없을 경우 <UNK>를 반환 한다.
토큰화 :
Training을 할 때 단어들에 따라서 인덱스에 mapping을 하여 어휘 사전을 만든다.
<UNK> :
이때 Test에서 Train때 못본 단어다 라고 한다면 어디로 mapping을 시켜줘야할 지 모르게 되는데,
그러한 경우 <UNK> 토큰에 넣게 된다.
[ 기계가 모르는 단어가 등장하면 그 단어를 단어 집합에 없는 단어란 의미에서 해당 토큰을 UNK라고 한다. ]
언어 모델에 있어서는 UNK가 치명적으로 작용한다.
Ex. 이전에 생성한 마지막 단어가 UNK일 경우 마지막 단어는 아무거나 나올 수 있기때문에 문제가 된다.
OoV가 미치는 영향
- 입력 데이터에 OoV가 발생할 경우, <UNK>토큰으로 치환하여 모델에 입력
-Ex. 나는 학교에 가서 밥을 먹었다. → 나 는 <UNK> 에 가 서 <UNK>을 먹 었 다. - 특히, 이전 단어들을 기반으로 다음 단어를 예측하는 task에서 치명적
-Ex. Natural Language Generation
해결 방안
BPE (Byte Pair Encording)알고리즘
서브워드 분리(Subword segmenation)
서브워드 분리(Subword segmenation)
하나의 단어는 더 작은 단위의 의미가 있는 여러 서브워드들의 조합으로 구성된 경우가 많다.
Ex. birthplace = birth + place
하나의 단어를 여러 서브워드로 분리해서 단어를 인코딩 및 임베딩 하겠다는 의도를 가진 전처리 작업이다.
이는 신조어, 희귀 단어, 등과 같은 문제를 완화시킬 수 있으며,
이런 작업을 하는 토크나이저를 서브워드 토크나이저라고 명명 한다.
BPE(Byte Pair Encoding)
- 1994년에 제안된 데이터 압축 알고리즘
- 이후 자연어 처리(NLP)의 서브워드 분리 알고리즘으로 응용되었다.
- 원리
- 연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합하는 방식을 수행한다.
BPE 예제(알고리즘 이해)
aaabdaaabac- 문자열 중 가장 자주 등장하고 있는 바이트의 쌍(Byte Pair)은 'aa' 이며,
이를 바이트의 쌍을 하나의 바이트인 'Z'로 치환
# Z=aa
ZabdZabac- 위 문자열 중에서 가장 많이 등장하고 있는 바이트의 쌍(Byte Pair)은 'ab'이며,
이를 바이트의 쌍을 하나의 바이트인 'Y'로 치환
# Z=aa, Y=ab
ZYdZYac- 문자열 중 가장 자주 등장하고 있는 바이트의 쌍(Byte Pair)은 'ZY' 이며,
이를 바이트의 쌍을 하나의 바이트인 'X'로 치환
# Z=aa, Y=ab, X=ZY
XdXac- 더 이상 병합할 바이트의 쌍은 없으므로 BPE는 위의 결과를 최종 결과로 하여 종료 된다.
NLP에서 BPE 알고리즘
- 대표적인 서브워드 분리 알고리즘
- Sennrich et al. (2016)에서 BPE알고리즘을 서브워드 분리 알고리즘으로 응용
- 기존에 있던 단어를 분리한다는 의미
- 글자(charcter)또는 유니코드(unicode)단위로 단어 집합(vocabulary)를 만들고,
가장 많이 등장하는 유니그램을 하나의 유니그램으로 통합한다.
NLP에서 BPE 예제
Tokenizer 이후 출력된 값
- 딕셔너리의 모든 단어들을 글자(chracter)단위로 분리 한다.
# dictionary
l o w : 5,
l o w e r : 2,
n e w e s t : 6,
w i d e s t : 3- 딕셔너리를 참고로 한 초기 단어 집합(vocabulary)은 아래와 같다.
- 초기 구성은 글자 단위로 분리된 상태
# vocabulary
l, o, w, e, r, n, w, s, t, i, d- 알고리즘의 동작을 몇 회 반복(iteration)할 것인지를 사용자가 정한다. (10회)
- 가장 빈도수가 높은 유니그램의 쌍을 하나의 유니그램으로 통합하는 과정을 총 10회 반복
- 1회 : 빈보수가 9회로 가장 높은 (e, s)의 쌍을 es로 통합
# dictionary update!
l o w : 5,
l o w e r : 2,
n e w es t : 6,
w i d es t : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es
- 2회 : 빈도수가 9회로 가장 높은 (es, t)의 쌍을 est로 통합
# dictionary update!
l o w : 5,
l o w e r : 2,
n e w est : 6,
w i d est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est
- 3회 : 빈도수가 7회로 가장 높은 (l, o)쌍을 lo로 통합
# dictionary update!
lo w : 5,
lo w e r : 2,
n e w est : 6,
w i d est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo
- 반복~
더보기
- 4회 : 빈도수가 7회로 가장 높은 (lo, w)쌍을 low로 통합
# dictionary update!
low : 5,
low e r : 2,
n e w est : 6,
w i d est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low
- 5회 : 빈도수가 6회로 가장 높은 (n, e)쌍을 ne로 통합
# dictionary update!
low : 5,
low e r : 2,
ne w est : 6,
w i d est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne
- 6회 : 빈도수가 6회로 가장 높은 (ne, w)쌍을 new로 통합
# dictionary update!
low : 5,
low e r : 2,
new est : 6,
w i d est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new
- 7회 : 빈도수가 6회로 가장 높은 (new, est)쌍을 newest로 통합
# dictionary update!
low : 5,
low e r : 2,
newest : 6,
w i d est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new, newest
- 8회 : 빈도수가 3회로 가장 높은 (w, i)쌍을 wi로 통합
# dictionary update!
low : 5,
low e r : 2,
newest : 6,
wi d est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new, newest, wi
- 9회 : 빈도수가 3회로 가장 높은 (wi, d)쌍을 wid로 통합
# dictionary update!
low : 5,
low e r : 2,
newest : 6,
wid est : 3# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid
- 10회 : 빈도수가 3회로 가장 높은 (wid, est)쌍을 widest로 통합
# dictionary update!
low : 5,
low e r : 2,
newest : 6,
widest : 3# vocabulary update!
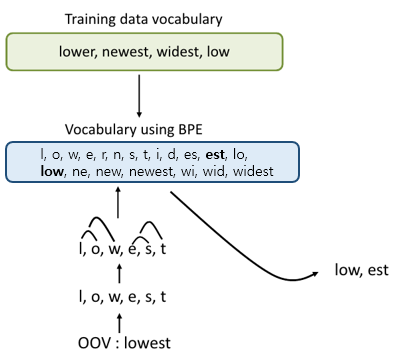
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid, widest- 이 경우 테스트 과정에서 'lowest'란 단어가 등장한다면, 기존에는 OoV에 해당되는 단어가 되었겠지만,
BPE 알고리즘을 사용한 단어 집합에서는 더 이상 'lowest'는 OoV가 아니다. - 기계는 우선 'lowest'를 전부 글자 단위로 분할 하며
- 'l, o, w, e, s, t' - 그 후 기계는 위의 단어 집합을 참고 하여 아래와 같은 단어집합을 찾아낸다.
-'low, est' - 즉, 이러한 방법으로 OoV를 해결 하게 된다.
BPE 장점
- 어쨌든 모르는 단어지만, 알고있는 subword들을 통해 의미를 유추해볼 수 있다.
- Ex. 버카충 - 이렇게 처리하면 OoV 문제 해결뿐만 아니라 희귀 단어, 신조어 같은 문제를 완화시킬 수 있다.
정리
- BPE 압축 알고리즘을 통해 통계쩍으로 더 작은 의미 단위(subword)로 분절 수행
- BPE를 통해 OoV를 없앨 수 있으며, 이는 성능상 매우 큰 이점으로 작용
- 한국어의 경우
- 띄어쓰기가 제멋대로인 경우가 많으므로,
normaluzation 없이 바로 subword segmentation을 적용하는 것은 위험하다.
- 따라서 형태소 분석기를 통한 tokenization을 진행한 이후,
subword segmentation을 적용하는 것을 권장
참고자료
- 딥 러닝을 이용한 자연어 처리 입문
호기심
1. BPE 알고리즘을 두 개 이상으로 단어를 상황에 맞게 압축을 동적으로 사용한다면?
기존 BPE 알고리즘에서 압축하는 한 쌍을 두 개를 기준으로 반복(iteration) 하는데,
이때, 압축을 정적으로 두 개만이 아닌 두 개 이상으로 글자(chracter)를 상황에 맞게 동적으로 사용한다면?
호기심을 갖게된 이유
- 압축을 정적으로 두 개만이 아닌 두 개 이상의 글자(charcter)를 상황에 맞게 동적으로 사용하면 좋을것 같다고 생각
1. 모든 데이터를 읽고 데이터 내에서 반복되는 규칙을 습득
2. 규칙이 있는 글자(chracter) 쌍을 태깅하여...?
3. 도매인에 특화된 성능을 증가시킬 수 있는 모델 제작에 의문이 생김3. ... 이러면 시간복잡도가 너무 올라가나? 방법이 없나... - - Answer :
기존 BPE 알고리즘은 많은 경우를 수용하기 위해
2. 반복 횟수가 낮다면, OoV가 여전히 발생 할 수 있을 것이라고 생각
호기심을 갖게된 이유
- "BPE의 특징은 알고리즘의 동작을 몇 회 반복(iteration)할 것인지를 사용자가 정한다." 라는 구절에서
반복 횟수가 낮다면, OoV가 여전히 발생 할 수 있을 것이라고 생각
해결 방법론?
- 1이하의 pair들의 빈도가 나올때까지 BPE 알고리즘을 반복(iteration)시킨다?
- Answer : ?
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- sep=
- arguments
- parameters
- matplotlib
- 재귀?
- recursive function
- 덮어쓰기
- 재귀함수 이해
- 이중 프린트
- 변수 덮어쓰기
- _meaning
- 콘다
- recursive
- list comprehension
- print()
- _의미
- 백준
- conda
- anaconda
- Python
- 이스케이프 코드
- 파이썬
- asd ad
- 재귀함수 설명
- sad asd
- sdsad
- 파이썬 변수
- underscore
- 연산속도
- d asd asd
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
글 보관함